
In this post will show how to implement CNTK 106 Tutorial in C#. This tutorial lecture is written in Python and there is no related example in C#. For this reason I decided to translate this very good tutorial into C#. The tutorial can be found at: CNTK 106: Part A – Time series prediction with LSTM (Basics) and uses sin wave function in order to predict time series data. For this problem the Long Short Term Memory, LSTM, Recurrent Neural Network is used.
Goal
The goal of this tutorial is prediction the simulated data of a continuous function ( sin wave). From 
")



The excitement of this tutorial is using the LSTM recurrent neural network which is nicely suited for this kind of problems. As you probably know LSTM is special recurrent neural network which has ability to learn from its experience during the training. More information about this fantastic version of recurrent neural network can be found here.
The blog post is divided into several sub-sections:
- Simulated data part
- LSTM Network
- Model training and evaluation
Since the simulated data set is huge, the original tutorial has two running mode which is described by the variable isFast. In case of fast mode, the variable is set to True, and this mode will be used in this tutorial. Later, the reader may change the value to False in order to see much better training model, but the training time will be much longer. The Demo for this this blog post exposes variables of the batch size and iteration number to the user, so the user may defined those numbers as he/she want.
Data generation
In order to generate simulated sin wave data, we are going to implement several helper methods. Let
- generateWaveDataset()
The generateWaveDataset takes the periodic function,set of independent values (which is corresponded the time for this case) and generate the wave function, by providing the time steps and time shift. The method is related to the generate_data() python methods from the original tutorial.
static Dictionary<string, (float[][] train, float[][] valid, float[][] test)> loadWaveDataset(Func<double, double> fun, float[] x0, int timeSteps, int timeShift)
{
////fill data
float[] xsin = new float[x0.Length];//all data
for (int l = 0; l < x0.Length; l++)
xsin[l] = (float)fun(x0[l]);
//split data on training and testing part
var a = new float[xsin.Length - timeShift];
var b = new float[xsin.Length - timeShift];
for (int l = 0; l < xsin.Length; l++)
{
//
if (l < xsin.Length - timeShift) a[l] = xsin[l]; // if (l >= timeShift)
b[l - timeShift] = xsin[l];
}
//make arrays of data
var a1 = new List<float[]>();
var b1 = new List<float[]>();
for (int i = 0; i < a.Length - timeSteps + 1; i++)
{
//features
var row = new float[timeSteps];
for (int j = 0; j < timeSteps; j++)
row[j] = a[i + j];
//create features row
a1.Add(row);
//label row
b1.Add(new float[] { b[i + timeSteps - 1] });
}
//split data into train, validation and test data set
var xxx = splitData(a1.ToArray(), 0.1f, 0.1f);
var yyy = splitData(b1.ToArray(), 0.1f, 0.1f);
var retVal = new Dictionary<string, (float[][] train, float[][] valid, float[][] test)>();
retVal.Add("features", xxx);
retVal.Add("label", yyy);
return retVal;
}
Once the data is generated, three datasets should be created: train, validate and test dataset, which are generated by splitting the dataset generated by the above method. The following splitData method splits the original sin wave dataset into three datasets,
static (float[][] train, float[][] valid, float[][] test) splitData(float[][] data, float valSize = 0.1f, float testSize = 0.1f)
{
//calculate
var posTest = (int)(data.Length * (1 - testSize));
var posVal = (int)(posTest * (1 - valSize));
return (data.Skip(0).Take(posVal).ToArray(), data.Skip(posVal).Take(posTest - posVal).ToArray(), data.Skip(posTest).ToArray());
}
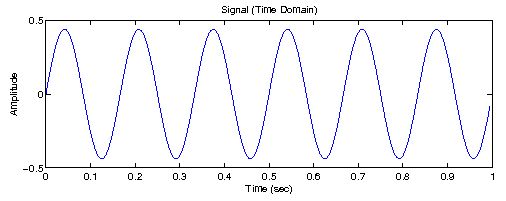
In order to visualize the data, the Windows Forms project is created. Moreover, the ZedGraph .NET class library is used in order to visualize the data. The following picture shows the generated data.

Network modeling
As mentioned on the beginning of the blog post, we are going to create LSTM recurrent neural network, with 1 LSTM cell for each input. We have N inputs and each input is a value in our continuous function. The N outputs from the LSTM are the input into a dense layer that produces a single output. Between LSTM and dense layer we insert a dropout layer that randomly drops 20% of the values coming from the LSTM to prevent overfitting the model to the training dataset. We want use use the dropout layer during training but when using the model to make predictions we don’t want to drop values.
The description above can be illustrated on the following picture:

The implementation of the LSTM can be sumarize in one method, but the real implementation can be viewed in the demo sample which is attached with this blog post.
The following methods implements LSTM network depicted on the image above. The arguments for the method are already defined.
public static Function CreateModel(Variable input, int outDim, int LSTMDim, int cellDim, DeviceDescriptor device, string outputName)
{
Func<Variable, Function> pastValueRecurrenceHook = (x) => CNTKLib.PastValue(x);
//creating LSTM cell for each input variable
Function LSTMFunction = LSTMPComponentWithSelfStabilization<float>(
input,
new int[] { LSTMDim },
new int[] { cellDim },
pastValueRecurrenceHook,
pastValueRecurrenceHook,
device).Item1;
//after the LSTM sequence is created return the last cell in order to continue generating the network
Function lastCell = CNTKLib.SequenceLast(LSTMFunction);
//implement drop out for 10%
var dropOut = CNTKLib.Dropout(lastCell,0.2, 1);
//create last dense layer before output
var outputLayer = FullyConnectedLinearLayer(dropOut, outDim, device, outputName);
return outputLayer;
}
Training the network
In order to train the model, the nextBatch() method is implemented that produces batches to feed the training function. Note that because CNTK supports variable sequence length, we must feed the batches as list of sequences. This is a convenience function to generate small batches of data often referred to as minibatch.
private static IEnumerable<(float[] X, float[] Y)> nextBatch(float[][] X, float[][] Y, int mMSize)
{
float[] asBatch(float[][] data, int start, int count)
{
var lst = new List<float>();
for (int i = start; i < start + count; i++) { if (i >= data.Length)
break;
lst.AddRange(data[i]);
}
return lst.ToArray();
}
for (int i = 0; i <= X.Length - 1; i += mMSize) { var size = X.Length - i; if (size > 0 && size > mMSize)
size = mMSize;
var x = asBatch(X, i, size);
var y = asBatch(Y, i, size);
yield return (x, y);
}
}
Note: Since the this tutorial is implemented as WinForms C# project which can visualize training and testing datasets, as well as it can show the best found model during the training process, there are lot of other implemented methods which are not mentioned here, but can be found in the demo source code attached in this blog post.
Key Insight
When working with LSTM the user should pay attention on the following:
Since LSTM must work with axes with unknown dimensions, the variables should be defined on different way as we could saw in the previous blog posts. So the input and the output variable are initialized with the following code listing:
// build the model
var feature = Variable.InputVariable(new int[] { inDim }, DataType.Float, featuresName, null, false /*isSparse*/);
var label = Variable.InputVariable(new int[] { ouDim }, DataType.Float, labelsName, new List<CNTK.Axis>() { CNTK.Axis.DefaultBatchAxis() }, false);
As specified in the original tutorial: “Specifying the dynamic axes enables the recurrence engine handle the time sequence data in the expected order. Please take time to understand how to work with both static and dynamic axes in CNTK as described here“, the dynamic axes is key point in LSTM.
Now the implementation is continue with the defining learning rate, momentum, the learner and the trainer.
var lstmModel = LSTMHelper.CreateModel(feature, ouDim, hiDim, cellDim, device, "timeSeriesOutput");
Function trainingLoss = CNTKLib.SquaredError(lstmModel, label, "squarederrorLoss");
Function prediction = CNTKLib.SquaredError(lstmModel, label, "squarederrorEval");
// prepare for training
TrainingParameterScheduleDouble learningRatePerSample = new TrainingParameterScheduleDouble(0.0005, 1);
TrainingParameterScheduleDouble momentumTimeConstant = CNTKLib.MomentumAsTimeConstantSchedule(256);
IList<Learner> parameterLearners = new List<Learner>() {
Learner.MomentumSGDLearner(lstmModel.Parameters(), learningRatePerSample, momentumTimeConstant, /*unitGainMomentum = */true) };
//create trainer
var trainer = Trainer.CreateTrainer(lstmModel, trainingLoss, prediction, parameterLearners);
Now the code is ready, and the 10 epochs should return acceptable result:
// train the model
for (int i = 1; i <= iteration; i++)
{
//get the next minibatch amount of data
foreach (var miniBatchData in nextBatch(featureSet.train, labelSet.train, batchSize))
{
var xValues = Value.CreateBatch<float>(new NDShape(1, inDim), miniBatchData.X, device);
var yValues = Value.CreateBatch<float>(new NDShape(1, ouDim), miniBatchData.Y, device);
//Combine variables and data in to Dictionary for the training
var batchData = new Dictionary<Variable, Value>();
batchData.Add(feature, xValues);
batchData.Add(label, yValues);
//train minibarch data
trainer.TrainMinibatch(batchData, device);
}
if (this.InvokeRequired)
{
// Execute the same method, but this time on the GUI thread
this.Invoke(
new Action(() =>
{
//output training process
progressReport(trainer, lstmModel.Clone(), i, device);
}
));
}
else
{
//output training process
progressReport(trainer, lstmModel.Clone(), i, device);
}
}
Model Evaluation
Model evaluation is implemented during the training process. In this way we can see the learning process and how the model is getting better and better.
Fore each minibatch the progress method is called which updates the charts for the training and testing data set.
void progressReport(Trainer trainer, Function model, int iteration, DeviceDescriptor device)
{
textBox3.Text = iteration.ToString();
textBox4.Text = trainer.PreviousMinibatchLossAverage().ToString();
progressBar1.Value = iteration;
reportOnGraphs(trainer, model, iteration, device);
}
private void reportOnGraphs(Trainer trainer, Function model, int i, DeviceDescriptor device)
{
currentModelEvaluation(trainer, model, i, device);
currentModelTest(trainer, model, i, device);
}
The following picture shows the training process, where the model evaluation is shown simultaneously, for the training and testing data set.
Also the simulation of the Loss value during the training is simulated as well.

As can be see the blog post extends the original Tutorial with some handy tricks during the training process. Also this demo is good strarting point for development bether tool for LSTM Time Series training. The full source code of this blog post, which shows much more implementation than presented in the blog post can be found here.

Pingback: CNTK C# LSTM Examples – program faq
full sourcecode link not available :(
The link is correct, please try one more time.
The example has as input a single feature, but what should I do if I have two features? Should I set hiDim to 2? How the data for the input should be sorted? This guide is really really helpful, many thanks…
Actually the example uses 5 features, because the sine function (time series data) is transformed into data frame with 5 features and one label.
First the sin wawe function is generated for 10 000 values. Those 10 000 values are transformed into data frame with 5 features and one label.
For example: let w1,w2,w3,w4,w5,w6,w7,…, w10000 represent sin values. The data frame with 5 features is generated on the following way.
feature1, feature2, feature3, feature4, feature5, label
w1, w2, w3, w4, w5, w6,
w2, w3, w4, w5, w6, w7,
……
. w9999, w10000
On this way we got data frame with 6 columns (5 features and one label ) and 9994 rows.
So the answer:
Feature dimension=5
Label dimension = 1.
Since label dimension is 1- this is typical regression problem.
Hope this help.
Many thanks for the clarification, what should I do if instead of one I had two input signals (ie one sine wave and one square wave) to predict a single output value?
Right, you have typical multi-variant time series case. So the previous case is repeated two times.
Say we have two time series:
ts1: w1,w2,w3,w4,w5,w6,w7,…, w10000
ts2: r1,r2,r3,r4,r5,r6,r7,…, r10000
and want to build one network model with 10 features (5+5) each and two labels (1+1)
Two time series are tranformed into data frame like the following:
feature1, feature2, feature3, …., feature9, feature10, label1, label2
w1, r1, w2, r2, w3, r3, w4, r4, w5, r5, w6, r6
w1,r2,w3, r3, w4, r4, w5, r5,w6,r6, w7,r7
……
So the answer:
Feature dimension=10
Label dimension = 2
Great explanation, many thanks. I’m training and it seems to work. I don’t want to take advantage of your kindness, but…. If I understand correctly, the two output values (labels) should be set equal and the dense layer uses these two results to generate a more precise value? Is it right to leave the number of hidden lstm layers equal to 1? Also what do you suggest to do if in some cases I have a missing value (feature) in the sequence?
Missing values must be fixed prior to create data sets.CNTK assume all data is available and prepared for training.
Pingback: CNTK C# LSTM Examples – ioloiip
Great explanation and easy to understand for beginners.
If there is a C# project that we can download so that without confusing in environment setup.
Thank you indeed for your consideration and reply
I am sorry that I lose the description as a source code attached.
Additional note that if your compiler required C# 7, you will need to install
System.ValueTuple
Microsoft.Net.Compilers
in your NutGet.